Convolutional Neural Network
Prequisite: Basic knowledge of Neural Network
Convolutional Neural Network is a supervised deep learning algorithm. It is used for image classification, recommender system and natural language processing. Image classification means categorization of image into particular class like finding cats out of cats and dogs. CNN is inspired by biological structure and process of animal’s virtual cortex.
Alike Neural Network (NN), CNN is also made of neurons with trainable weights and biases. A neuron takes weighted sum input from previous layer neurons, and apply an activation function to it. The whole CNN model has a loss function, on training by input-output sets, weights and biases are trained so as to decrease the loss function. The first difference between CNN and NN is that, NN’s input is a vector and CNN’s input is a multi-channeled image (RGB color channels).
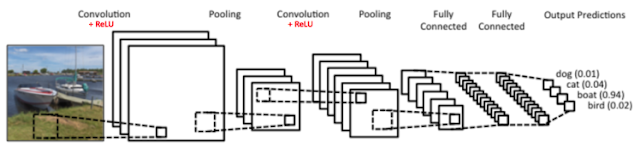 CNN consists of input-output layers and in between hidden layers. Input layer is set of pixels of input image, whereas output layer is set of classes. Hidden layers are not fully connected to input layer. A neuron in hidden layers is related to only a portion of neurons in input layers, it means that neuron has information or feature related to a part of the image only. Value returned by a neuron can be treated as a feature, and as the layer succeeded next, higher level complex features are generated based on previous layer features. High number of layers increase the accuracy of model, as they involve more high level complex features.
CNN consists of input-output layers and in between hidden layers. Input layer is set of pixels of input image, whereas output layer is set of classes. Hidden layers are not fully connected to input layer. A neuron in hidden layers is related to only a portion of neurons in input layers, it means that neuron has information or feature related to a part of the image only. Value returned by a neuron can be treated as a feature, and as the layer succeeded next, higher level complex features are generated based on previous layer features. High number of layers increase the accuracy of model, as they involve more high level complex features.
 The hidden layers of a CNN typically consist of Convolutional layers, ReLU layer, pooling layers and fully connected layers. Before fully connected layers (exact Neural Network), convolution and pooling is done repetitively.
The hidden layers of a CNN typically consist of Convolutional layers, ReLU layer, pooling layers and fully connected layers. Before fully connected layers (exact Neural Network), convolution and pooling is done repetitively.
Convolutional Neural Network is a supervised deep learning algorithm. It is used for image classification, recommender system and natural language processing. Image classification means categorization of image into particular class like finding cats out of cats and dogs. CNN is inspired by biological structure and process of animal’s virtual cortex.
Alike Neural Network (NN), CNN is also made of neurons with trainable weights and biases. A neuron takes weighted sum input from previous layer neurons, and apply an activation function to it. The whole CNN model has a loss function, on training by input-output sets, weights and biases are trained so as to decrease the loss function. The first difference between CNN and NN is that, NN’s input is a vector and CNN’s input is a multi-channeled image (RGB color channels).


Convolutional layer
Convolutional layer is the core of CNN. As an image have very high number of pixels, the input layer for image input is high-dimensional data. Number of neurons in hidden layers are also high for images. Fully connected layers in all stage will lead high Computational complexity. That’s why each neuron in Convolutional layer is connected to small region of the volume. This is achieved by Convolution operation.
Two dimensional Convolution operation:
Convolutional layer is the core of CNN. As an image have very high number of pixels, the input layer for image input is high-dimensional data. Number of neurons in hidden layers are also high for images. Fully connected layers in all stage will lead high Computational complexity. That’s why each neuron in Convolutional layer is connected to small region of the volume. This is achieved by Convolution operation.
Two dimensional Convolution operation:
A neuron in Convolutional layer correspond to a feature based on spatial relationship from the small region of input volume. Starting Convolutional layers detects small features such as edges. As the layers becomes deep features becomes more complexed by combination of previous simple features.
In convolutional layer, a set of n independent filters (Kernel) are used, which are independently convolved with the input layer volume. It results n feature maps. In starting, all Kernel matrix are initialized randomly. The values of Kernel matrix come from training of the CNN model.

Pooling layer

Pooling layer is dimensionality reduction of input feature map. It reduces size of feature map progressively. Pooling is applied independently to all feature maps. It is applied without doing overlapping.
Many types of pooling are used: Max, Average, Sum etc. Max pooling is used mostly, as high value corresponds high degree of feature presence. In Max Pooling, maximum value is chosen and other values are discarded from the input part.
Pooling is done because once the feature is detected in image, it exact relative position does not remain valuable. Feature’s position may vary in various objects of same class. For example relative position of eyes and nose may vary slightly in different faces.
Rectified Linear Unit (ReLU)

The Rectified Linear Unit (ReLU) is an activation function. It computes the function f(u)=max(0,u). It discards negative numbers, and keeps positive numbers exactly as they was. It is used preferably in CNN, and it gives faster training as compare to Sigmoid and tanh activation functions.
Fully Connected layers


The purpose of the Fully Connected layer is to use high-level features for classifying the input image into various classes based on the training dataset. Output layer assign prediction value that the given image belongs to what extent to specific class. Proper thresholding is needed to assign an object to a class correctly.
Comments
Post a Comment